Introduction
We will describe how to set up a data streaming pipeline from AWS DynamoDB to Athena using various AWS services.
This solution will result in a replication of the DynamoDB in Athena.
Architecture Overview
The solution will involve the following components:
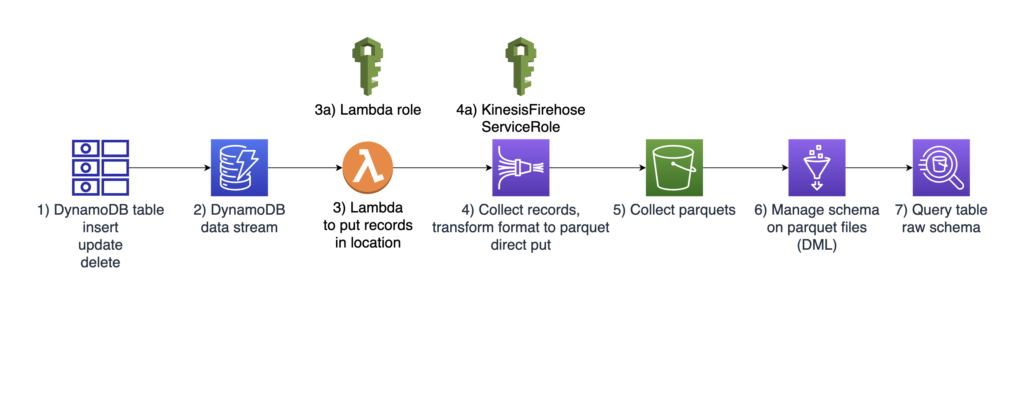
DynamoDB: The source database where Jargonic tables reside.
DynamoDB Stream: A stream attached to the DynamoDB table that captures changes to the data.
Lambda: A serverless function that processes DynamoDB stream records and transforms them for further processing.
Lambda Role: IAM role that grants necessary permissions to the Lambda function.
Kinesis Firehose: Streams processed data from Lambda to an S3 bucket.
Kinesis Firehose Role: IAM role that grants necessary permissions to Kinesis Firehose.
S3 Bucket: Stores the streamed data in a structured format.
Glue Table: Catalogs the data in S3, making it queryable by Athena.
Athena: Allows SQL queries on data stored in the Glue table.